


Kubernetes-ReplicaSet控制器
在实际使用的时候并不会直接使用 Pod,而是会使用各种控制器,Kubernetes 中运行了一系列控制器来确保集群的当前状态与期望状态保持一致,它们就是 Kubernetes 的大脑。例如,ReplicaSet 控制器负责维护集群中运行的 Pod 数量;Node 控制器负责监控节点的状态,并在节点出现故障时及时做出响应。总而言之,在 Kubernetes 中,每个控制器只负责某种类型的特定资源。
控制器
Kubernetes 控制器会监听资源的 创建/更新/删除 事件,并触发 Reconcile 调谐函数作为响应,整个调整过程被称作 “Reconcile Loop”(调谐循环) 或者 “Sync Loop”(同步循环)。Reconcile 是一个使用资源对象的命名空间和资源对象的名称来调用的函数,使得资源对象的实际状态与 资源清单中定义的状态保持一致。调用完成后,Reconcile 会将资源对象的状态更新为当前实际状态。下面的一段伪代码来表示这个过程:
for {
desired := getDesiredState() // 期望的状态
current := getCurrentState() // 当前实际状态
if current == desired { // 如果状态一致则什么都不做
// nothing to do
} else { // 如果状态不一致则调整编排,到一致为止
// change current to desired status
}
}
这个编排模型就是 Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。
ReplicaSet
假如现在有一个 Pod 正在提供线上的服务,想象一下可能会遇到的一些场景:
- 某次活动非常成功,网站访问量突然暴增
- 运行当前 Pod 的节点发生故障了,Pod 不能正常提供服务了
第一种情况,可能比较好应对,活动之前可以大概计算下会有多大的访问量,提前多启动几个 Pod 副本,活动结束后再把多余的 Pod 杀掉,虽然有点麻烦,但是还是能够应对这种情况的。
第二种情况,可能某天夜里收到大量报警说服务挂了,然后起来打开电脑在另外的节点上重新启动一个新的 Pod,问题可以解决。
但是如果都人工的去解决遇到的这些问题,似乎又回到了以前刀耕火种的时代了,如果有一种工具能够自动管理 Pod 就好了,Pod 挂了自动在合适的节点上重新启动一个 Pod,这样遇到上面的问题就不需要手动去解决了。
而 ReplicaSet 这种资源对象就可以来实现这个功能,ReplicaSet(RS) 的主要作用就是维持一组 Pod 副本的运行,保证一定数量的 Pod 在集群中正常运行,ReplicaSet 控制器会持续监听它所控制的这些 Pod 的运行状态,在 Pod 发送故障数量减少或者增加时会触发调谐过程,始终保持副本数量一定。
和 Pod 一样仍然还是通过 YAML 文件来描述 ReplicaSet 资源对象,如下 YAML 文件是一个常见的 ReplicaSet 定义:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-rs
namespace: default
spec:
replicas: 3 # 期望的Pod副本数量 默认是1
selector: # Label Selector 必须匹配Pod模板中的标签
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
limits:
memory: "128Mi"
cpu: "500m"
上面的 YAML 文件结构和之前定义的 Pod 看上去没太大两样,有常见的 apiVersion、kind、metadata,在 spec 下面描述 ReplicaSet 的基本信息,其中包含 3 个重要内容:
- replias:表示期望的 Pod 的副本数量
- selector:Label Selector,用来匹配要控制的 Pod 标签,需要和下面的 Pod 模板中的标签一致
- template:Pod 模板,实际上就是以前我们定义的 Pod 内容,相当于把一个 Pod 的描述以模板的形式嵌入到了 ReplicaSet 中来。
上面就是一个普通的 ReplicaSet 资源清单文件,ReplicaSet 控制器会通过定义的 Label Selector 标签去查找集群中的 Pod 对象:

直接来创建上面的资源对象:
kubectl apply -f nginx-rs.yaml
通过查看 RS 可以看到当前资源对象的描述信息,包括DESIRED、CURRENT、READY的状态值,创建完成后,可以利用如下命令查看 Pod 列表。
kubectl get rs -n default
kubectl get pod -n default -l app=nginx
可以看到现在有 3 个 Pod,这 3 个 Pod 就是在 RS 中声明的 3 个副本,删除其中一个 Pod,再次查看pod列表
kubectl delete pod nginx-rs-9ndjb -n default

可以看到又重新出现了一个 Pod,这个就是上面说的 ReplicaSet 控制器做的工作,在 YAML 文件中声明了 3 个副本,然后删除了一个副本,变成了两个,这个时候 ReplicaSet 控制器监控到控制的 Pod 数量和期望的 3 不一致,就需要启动一个新的 Pod 来保持 3 个副本,这个过程就是上面说的调谐的过程。同样可以查看 RS 的描述信息来查看到相关的事件信息:
kubectl describe rs nginx-rs -n default
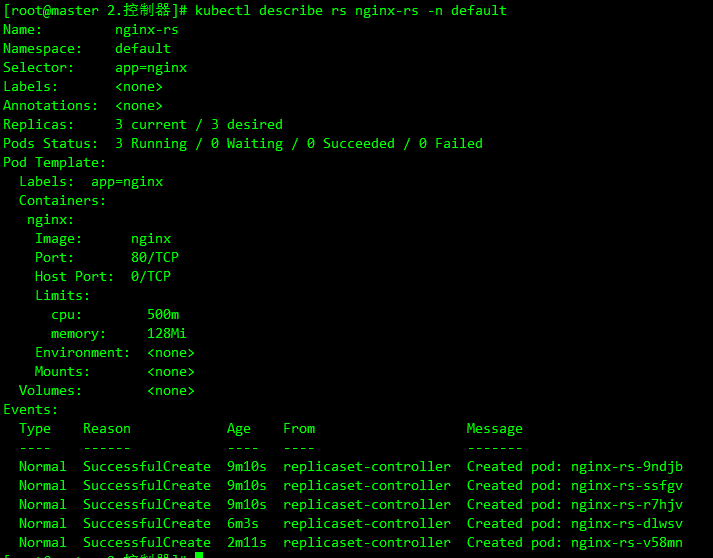
可以发现最开始通过 ReplicaSet 控制器创建了 3 个 Pod,后面删除了 Pod 后, ReplicaSet 控制器又创建了一个 Pod,和上面的描述是一致的。如果这个时候把 RS 资源对象的 Pod 副本更改为 2 spec.replicas=2,这个时候再更新下资源对象:
kubectl apply -f nginx-rs.yaml
kubectl describe rs nginx-rs -n default
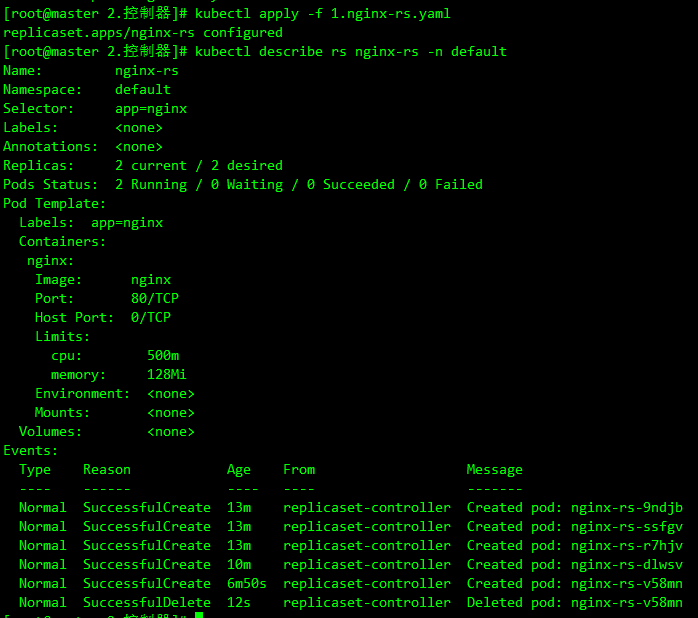

可以看到 Replicaset 控制器在发现资源声明中副本数变更为 2 后,就主动去删除了一个 Pod,这样副本数就和期望的始终保持一致了
随便查看一个 Pod 的描述信息可以看到这个 Pod 的所属控制器信息:
kubectl describe pod nginx-rs-r7hjv -n default

另外被 ReplicaSet 持有的 Pod 有一个 metadata.ownerReferences 指针指向当前的 ReplicaSet,表示当前 Pod 的所有者,这个引用主要会被集群中的垃圾收集器使用以清理失去所有者的 Pod 对象。这个 ownerReferences 和数据库中的外键非常类似。可以通过将 Pod 资源描述信息导出查看:
kubectl get pod nginx-rs-r7hjv -n default -o yaml
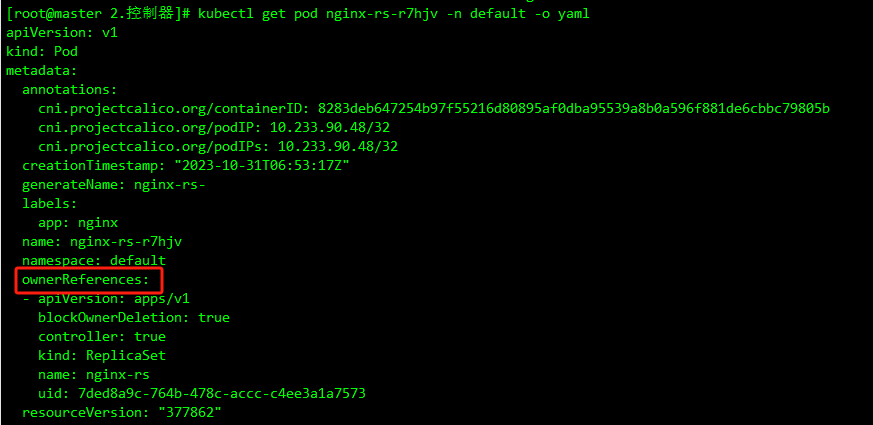
可以看到 Pod 中有一个 metadata.ownerReferences 的字段指向了 ReplicaSet 资源对象。如果要彻底删除 Pod,我们就只能删除 RS 对象:
kubectl delete rs nginx-rs -n default
Replication Controller(可忽略)
Replication Controller 简称 RC,实际上 RC 和 RS 的功能几乎一致,RS 算是对 RC 的改进,目前唯一的一个区别就是 RC 只支持基于等式的 selector(env=dev 或 environment!=qa),但 RS 还支持基于集合的 selector(version in (v1.0, v2.0))。
比如上面资源对象如果要使用 RC 的话,对应的 selector 是这样的:
selector:
app: nginx
RC 只支持单个 Label 的等式,而 RS 中的 Label Selector 支持 matchLabels 和 matchExpressions 两种形式:
selector:
matchLabels:
app: nginx
---
selector:
matchExpressions: # 该选择器要求 Pod 包含名为 app 的标签
- key: app
operator: In
values: # 并且标签的值必须是 nginx
- nginx
总的来说 RS 是新一代的 RC,所以以后直接使用 RS 即可,它们的功能都是一致的,但是实际上在实际使用中不会直接使用 RS,而是使用更上层的类似于 Deployment 这样的资源对象。