


Kubernetes-HPA控制器
在前面使用了一个 kubectl scale 命令可以来实现 Pod 的扩缩容功能,但是这个是完全手动操作的,要应对线上的各种复杂情况,需要能够做到自动化去感知业务,来自动进行扩缩容。为此,Kubernetes 也提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称 HPA,HPA通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量,这是 HPA 最基本的原理:

可以简单的通过 kubectl autoscale 命令来创建一个 HPA 资源对象,HPA Controller 默认30s轮询一次(可通过 kube-controller-manager 的--horizontal-pod-autoscaler-sync-period 参数进行设置),查询指定的资源中的 Pod 资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
Metrics Server
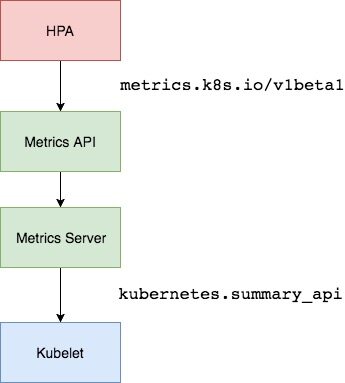
在 HPA 的第一个版本中,需要 Heapster 提供 CPU 和内存指标,在 HPA v2 之后就需要安装 Metrcis Server 了,Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,有了 Metrics Server 之后,就完全可以通过标准的 Kubernetes API 来访问想要获取的监控数据了:
https://10.96.0.1/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
比如访问上面的 API 的时候,就可以获取到该 Pod 的资源数据,这些数据其实是来自于 kubelet 的 Summary API 采集而来的。不过需要说明的是这里可以通过标准的 API 来获取资源监控数据,并不是因为 Metrics Server 就是 APIServer 的一部分,而是通过 Kubernetes 提供的 Aggregator 汇聚插件来实现的,是独立于 APIServer 之外运行的。
安装
本集群时通过kubekey安装的,只需要把配置里的 metrics_server.enabled 改成 true,等几分钟就可以了
metrics_server:
enabled: true

HPA对象
用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容。资源清单如下所示:hpa-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80
然后直接创建 Deployment,注意一定先把之前创建的具有 app=nginx 的 Pod 先清除掉:
kubectl apply -f hpa-demo.yaml
kubectl get pods -n default -l app=nginx

现在创建一个 HPA 资源对象,可以使用kubectl autoscale命令来创建:
kubectl autoscale deployment hpa-demo -n default --cpu-percent=10 --min=1 --max=10

此命令创建了一个关联资源 hpa-demo 的 HPA,最小的 Pod 副本数为 1,最大为 10。HPA 会根据设定的 cpu 使用率(10%)动态的增加或者减少 Pod 数量。
依然还是可以通过创建 YAML 文件的形式来创建 HPA 资源对象。如果不知道怎么编写的话,可以查看上面命令行创建的 HPA 的 YAML 文件:
kubectl get hpa hpa-demo -n default -o yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: "2023-11-02T08:34:21Z"
name: hpa-demo
namespace: default
resourceVersion: "712073"
uid: 0016dc58-7224-4f17-a7ef-c37ef621f94e
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 10
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-demo
status:
conditions:
- lastTransitionTime: "2023-11-02T08:34:36Z"
message: recent recommendations were higher than current one, applying the highest
recent recommendation
reason: ScaleDownStabilized
status: "True"
type: AbleToScale
- lastTransitionTime: "2023-11-02T08:34:36Z"
message: the HPA was able to successfully calculate a replica count from cpu resource
utilization (percentage of request)
reason: ValidMetricFound
status: "True"
type: ScalingActive
- lastTransitionTime: "2023-11-02T08:34:36Z"
message: the desired count is within the acceptable range
reason: DesiredWithinRange
status: "False"
type: ScalingLimited
currentMetrics:
- resource:
current:
averageUtilization: 0
averageValue: "0"
name: cpu
type: Resource
currentReplicas: 1
desiredReplicas: 1
可以根据上面的 YAML 文件就可以自己来创建一个基于 YAML 的 HPA 描述文件了。查看下这个 HPA 对象的信息:
kubectl describe hpa hpa-demo -n default
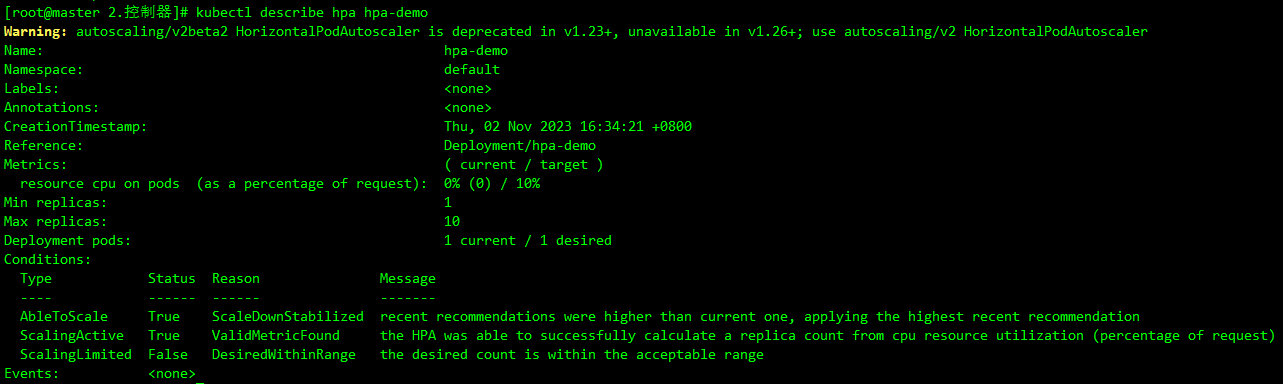
如果在事件信息里面出现了 failed to get cpu utilization: missing request for cpu 这样的错误信息。这是因为创建的 Pod 对象没有添加 request 资源声明,这样导致 HPA 读取不到 CPU 指标信息,所以如果要想让 HPA 生效,对应的 Pod 资源必须添加 requests 资源声明。
这是没有添加resources的事件信息:

现在增大负载进行测试,创建一个 busybox 的 Pod,并且循环访问上面创建的 Pod:
kubectl get pod -n default -o wide

kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh

可以看到CPU达到了29%且已经自动拉起了几个新的 Pod,查看资源 hpa-demo 的副本数量,副本数量已经从原来的 1 变成了 3 个:
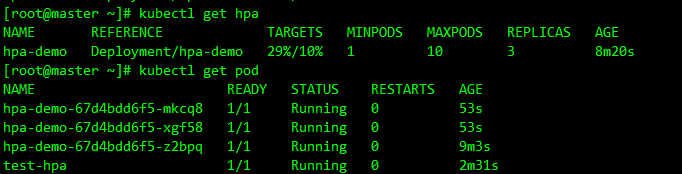
kubectl describe hpa hpa-demo -n default

关掉 busybox 来减少负载,然后等待一段时间观察下 HPA 和 Deployment 对象:

从 Kubernetes v1.12 版本开始可以通过设置 kube-controller-manager 组件的--horizontal-pod-autoscaler-downscale-stabilization 参数来设置一个持续时间,用于指定在当前操作完成后,HPA 必须等待多长时间才能执行另一次缩放操作。默认为5分钟,也就是默认需要等待5分钟后才会开始自动缩放。
内存
要使用基于内存或者自定义指标进行扩缩容(现在的版本都必须依赖 metrics-server 这个项目)。再用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容。资源清单如下所示:hpa-mem-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-mem-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
volumes:
- name: increase-mem-script
configMap:
name: increase-mem-config
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "50Mi"
cpu: "50m"
ports:
- containerPort: 80
volumeMounts:
- name: increase-mem-script
mountPath: /etc/script
securityContext:
privileged: true
这里和前面普通的应用有一些区别,将一个名为 increase-mem-config 的 ConfigMap 资源对象挂载到了容器中,该配置文件是用于后面增加容器内存占用的脚本,配置文件如下所示:increase-mem-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: increase-mem-config
data:
increase-mem.sh: |
#!/bin/bash
mkdir /tmp/memory
mount -t tmpfs -o size=40M tmpfs /tmp/memory
dd if=/dev/zero of=/tmp/memory/block
sleep 60
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory
由于这里增加内存的脚本需要使用到 mount 命令,这需要声明为特权模式,所以添加了 securityContext.privileged=true 这个配置。直接创建上面的资源对象即可:
kubectl apply -f increase-mem-cm.yaml
kubectl apply -f hpa-mem-demo.yaml
kubectl get pod -n default -l app=nginx

然后需要创建一个基于内存的 HPA 资源对象:hpa-mem.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-mem-demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-mem-demo
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageUtilization: 30
kubectl apply -f hpa-mem.yaml
kubectl get hpa -n default

到这里证明 HPA 资源对象已经部署成功了,接下来对应用进行压测,将内存压上去,直接执行上面挂载到容器中的 increase-mem.sh 脚本即可:
kubectl exec -it hpa-mem-demo-fcff6c67-89pst -- /bin/bash

可以看到内存使用已经超过了设定的 30% 这个阈值了,HPA 资源对象也已经触发了自动扩容,变成了 4 个副本了。
当内存释放掉后,controller-manager 默认 5 分钟过后会进行缩放,到这里就完成了基于内存的 HPA 操作。